Logographic Subword Model for Neural Machine Translation
Yihao Fang, Rong Zheng, Xiaodan Zhu
|
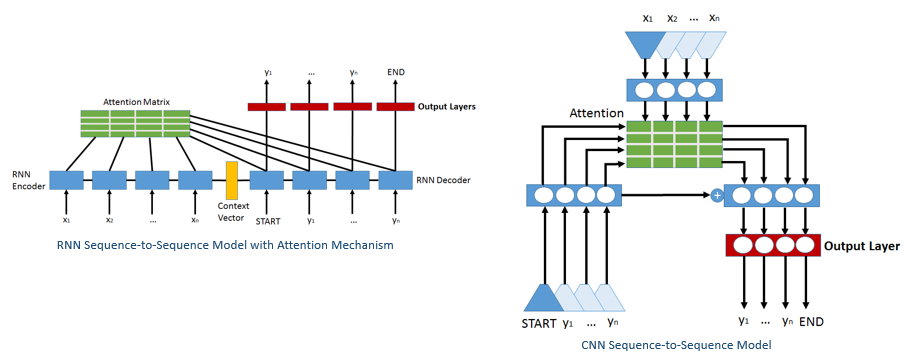
The sequence-to-sequence (seq2seq) models have been widely adopted in machine translation tasks. There are two important types of seq2seq models: the recurrent neural network (RNN) based seq2seq models [1] and the convolutional neural network (CNN) based sequence-to-sequence models [2]. The Recurrent Neural Network (RNN) sequence to sequence (seq2seq) model has RNNs as both its encoder and decoder. Compared to the RNN seq2seq models, the CNN seq2seq models substitute RNN components with CNN and allow much faster training while retaining the BLEU scores closely comparable to those obtained with RNN seq2seq models.
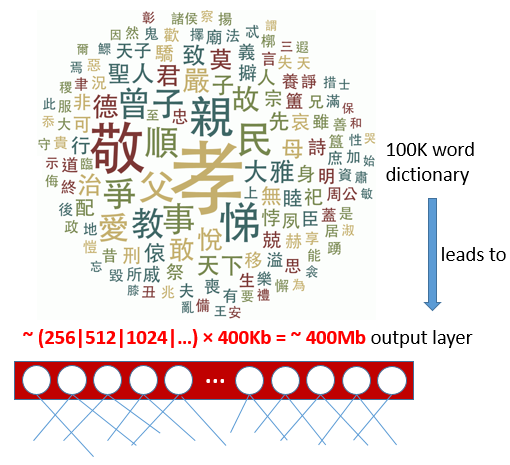
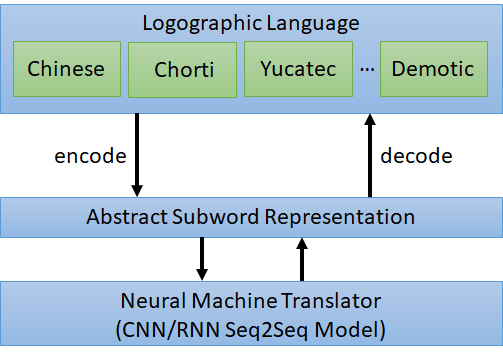
Despite the success of deep learning models in machine translation, their high computing complexity still strongly limits their applications such as those running on offline handheld translators. In machine translation, the size of the output layer is often proportional to the size of the target dictionary. Compacting the target dictionary consequently reduces the model size and speeds up model training and inference. To compact the target dictionary, we propose a logographic subword model that represents logograms as multiple “abstract subwords”.
Abstract subwords are code symbols which are independent on a particular language. These symbols are shared among words, and thus there will be much fewer symbols in both the source and target dictionaries.
The proposed logographic subword model consists of an encoder and a decoder. The encoder transforms a word into multiple abstract subwords (code symbols), The decoder transforms multiple abstract subwords into a word. Only abstract subwords directly participate in the training of the sequence-to-sequence models. This additional layer of abstraction reduces the model size, because a smaller dictionary of abstract subwords leads to an output layer with fewer units in the neural network.
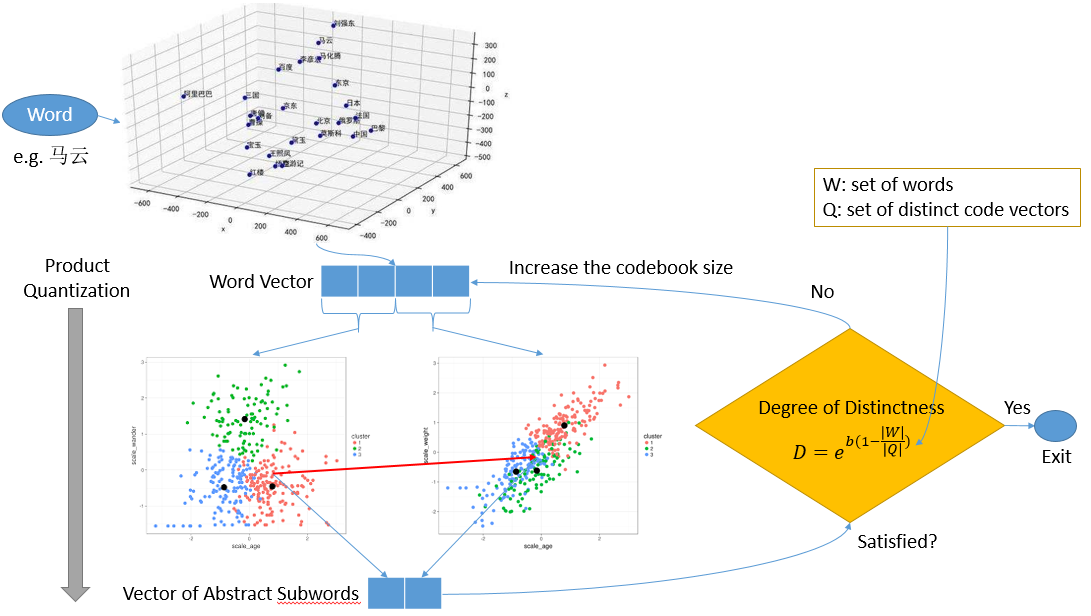
To encode a word to a vector of abstract subwords: First, a word is represented as a coordinate vector in word embeddings. Second, we product quantize the vector from step (1) to a vector of abstract subwords. Next, if degree of distinctness is satisfied, the algorithm exits; otherwise, we increase the codebook size, and perform product quantitation again.
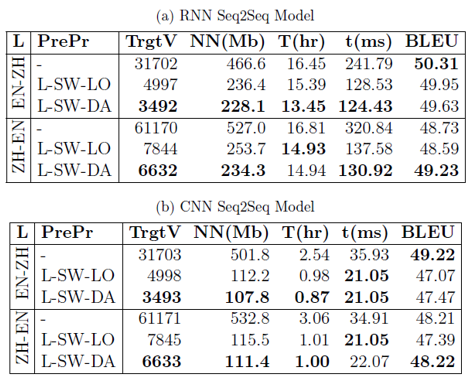
Model sizes (NN), training time (T) and inference time (t) are measured. We observe that in the English-to-Chinese translation task, the model sizes are reduced by \(37\%\) and \(77\%\) respectively with RNN and CNN; the training time is \(11\%\) and \(73\%\) shorter; and the inference time is nearly halved in RNN and \(36\%\) shorter in CNN.
The proposed approach has been shown with experiments to reduce model sizes as well as shorten training and inference time for both RNN and CNN sequence-to-sequence models. It is promising for reducing the complexity of other computationally expensive NLP problems with potential impact on large-dictionary real-time offline applications such as translation or dialog systems on offline mobile platforms. References
|